ЕВОЛЮЦІЙНІ ОПЕРАЦІЇ ТА ОСОБЛИВОСТІ ЇХ ЗАСТОСУВАННЯ ДЛЯ ВИРІШЕННЯ ЗАДАЧІ ГЕНЕРАЦІЇ ТЕСТОВИХ ДАНИХ
13.03.2024 00:15
[1. Information systems and technologies]
Author: Бердник Михайло Геннадійович, доктор технічних наук, доцент, Національний технічний університет «Дніпровська політехніка»; Захаров Дмитро Ігорович, аспірант, Національний технічний університет «Дніпровська політехніка»; Стародубський Ігор Петрович, аспірант, Національний технічний університет «Дніпровська політехніка»
Генерація тестових даних за допомогою генетичних алгоритмів має велике значення в сучасному світі інформаційних технологій. На сьогоднішній день обсяги даних зростають експоненційно, що ставить перед вченими і інженерами серйозні виклики у плані ефективного використання та обробки цих даних. Для успішного розвитку та впровадження різноманітних технологій, таких як машинне навчання, інтернет речей тощо, необхідно мати великі та репрезентативні набори тестових даних. Однією з основних проблем у цьому контексті є складність та часові затрати на ручну генерацію тестових даних. Застосування генетичних алгоритмів для автоматизованої генерації тестових наборів даних стає актуальним рішенням цієї проблеми. Генетичні алгоритми можуть прискорити процес генерації тестових даних, знизити витрати на ресурси та забезпечити більшу репрезентативність наборів даних. Ще однією важливою проблемою є потреба у генерації штучних даних для тестування та валідації моделей. У багатьох сценаріях реальних застосувань може бути складно зібрати достатню кількість реальних даних для виконання ефективного тестування. В таких випадках генерація штучних даних за допомогою генетичних алгоритмів може стати вирішальною у можливості виконання тестування моделей та алгоритмів на початкових етапах розробки. Генетичні алгоритми можуть стати важливим інструментом у процесах тестування, допомагаючи підтримувати високу якість тестових даних та забезпечуючи їхню репрезентативність. Отже, актуальність теми полягає у потребі розвитку ефективних та автоматизованих методів генерації тестових даних, які можуть відповісти на виклики сучасного світу технологій та забезпечити підтримку для швидкого розвитку та впровадження нових технологій.
Першим етапом у роботі генетичного алгоритму (ГА) є створення початкової популяції. У звичайній ситуації це робиться випадковим чином: перша група хромосом заповнюється випадковими значеннями тестових змінних, розподіленими рівномірно в межах визначених областей. Навіть існують інші способи ініціалізації, але саме випадковий вибір використовується тут, оскільки це забезпечує різноманіття в початковій популяції. Після формування початкової популяції розпочинається виконання основних еволюційних операцій за алгоритмом ГА. В роботі розглядається особливості їх застосування в задачі генерації тестових даних, також мінімальні критерії якості згенерованих вхідних даних.
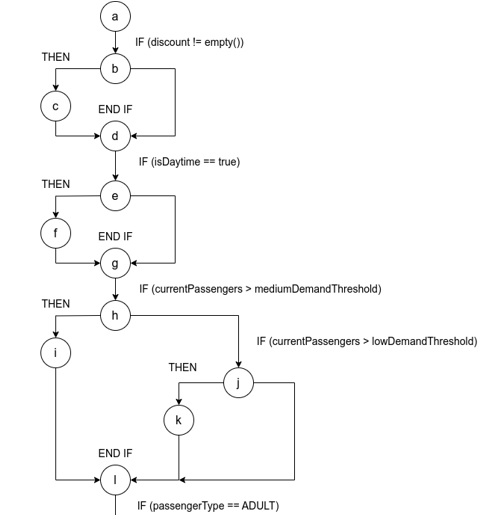
Для вирішення задачі оцінки критерія якості пропонується використовувати граф потоку виконання (ГПВ) програми та за допомогою відображення на ньому потоку виконання специфічного згенерованого набору тестових даних переконатися, що цей набір даних як мінімум забезпечує проходження кожної гілки коду, що визначається також критеріями методу тестування під назвою “покриття рішень” (branch testing). ГПВ служить цінним інструментом для розуміння поведінки програми та оцінки придатності тестових даних у дослідженні різних шляхів виконання.
Наприклад, розглянемо програму розрахунку кінцевої вартості білету для залізничного транспорту:
Для розуміння якості генерації набору тестових даних для наведеного коду побудований ГПВ, який відображає усі потоки виконання програми. Граф потоку виконання приведений на рис. 1.
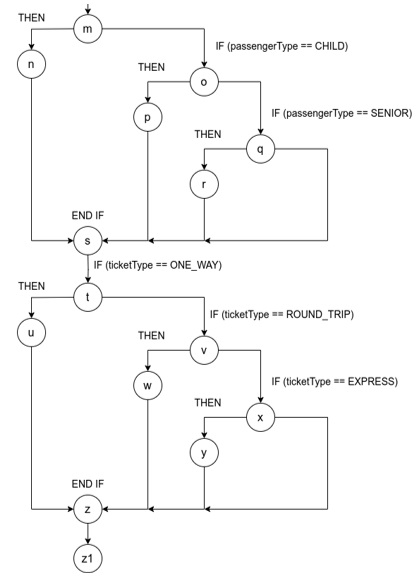
За допомогою програмного забезпечення, розробленого на базі генетичних алгоритмів було згенеровано набір даних. На рис. 2 можна побачити, що достатньо лише 3 наборів тестових даних для мінімального покриття кожної гілки виконання. Синім кольором вказано потік виконання першого набору даних, червоним другого і зеленим третього. Такий критерій можна вважати як мінімальний для якості згенерованого набору тестових даних. Отже, повертаючись до питання створення оптимального набору тестових даних, ключову роль у генерації тестових даних грають еволюційні оператори. Розглянемо такі еволюційні операції, як селекція, схрещування, змішування та мутація.
Селекція. Хромосоми у популяції впорядковані відповідно до значення функції пристосованості. Ця упорядкованість дозволяє розділити хромосоми на кращі (з вищим значенням функції) та гірші (з нижчим значенням функції), що є необхідним критерієм для виконання відбору. Перед етапом відбору частина кращих хромосом без змін переносяться у нове покоління, утворюючи таким чином пул кращих хромосом. Решта хромосом нового покоління будуть отримані в результаті схрещування. Саме для визначення пула, придатних для схрещування, хромосом здійснюється операція відбору. Пул кращих хромосом (Pbest) та пул хромосом для схрещування (Pcross) можуть збігатися або не збігатися. Головна мета відбору полягає у виборі пар батьківських хромосом, які будуть використані для формування нащадків.
Можна виділити наступні основні методи відбору батьківських пар:
1. Послідовні пари. Для схрещування відбираються послідовно розташовані в популяції хромосоми. Якщо популяція складається з m хромосом {x1, x1,…, xm}, то для хромосоми xi відбирається наступна за нею xi+1. Отже, один з батьків завжди буде обраний з підмножини непарних хромосом {x1, x1, x5, …}, а інший – з підмножини парних {x2, x4, x6,…}. Такий спосіб відбору простий у розумінні та реалізації, але негативно впливає на різноманіття популяції.
Рис 1. — Граф потоку виконання програми
Рис 2. — Граф потоку виконання програми з відображенням проходження для кожного набору тестових даних
2. Випадкове визначення пар. Кожна хромосома з пула для схрещування Pcross має однакову ймовірність бути вибраною. Випадкове визначення дозволяє забезпечити достатню варіативність у популяції, але може негативно вплинути на швидкість збіжності при великому розмірі Pcross.
3. Метод рулетки. Цей метод функціонально схожий із попереднім, але ймовірність вибору хромосоми задається пропорційно значенню її функції пристосованості. У відношенні до задачі генерації тестових даних, хромосоми, які ініціюють проходження по більш складних шляхах, мають більшу ймовірність бути вибраними для схрещування.
Ймовірність відбору може бути визначена наступним чином:
– oцінка за рангом. Оскільки в популяції хромосоми впорядковані за значенням функції пристосованості, позиція може виконувати роль рангу хромосоми. Ймовірність відбору залежить від рангу і може бути розрахована за формулою:
де P (xi)– ймовірність відбору тестового набору xi, mcross – кількість хромосом у пулі для схрещування, mj – ранг хромосоми.
–врахування за значенням. У цьому методі ймовірність відбору прямо залежить від значення функції пристосованості:
де F(xi), F(xj) – значення функції пристосованості для xi та xj. Цей метод найкраще працює, коли популяція складається з хромосом з майже однаковими значеннями функції пристосованості. В іншому випадку ймовірність відбору хромосом з високим значенням функції пристосованості може бути значно вищою, ніж у інших.
4. Турнірний відбір. Особливістю турнірного відбору є попередній вибір невеликої підмножини хромосом, у якій обирається хромосома з найбільшою функцією пристосованості. Турнірний відбір є одним із найбільш успішних методів відбору, але для його використання необхідно визначення додаткового параметра розміру підмножини попереднього вибору.
Методи відбору мають свої переваги та недоліки. Найбільший інтерес представляють методи турнірного відбору та випадкового вибору пар. Перший метод дозволяє розділити популяцію на окремі підгрупи, у яких відбувається відбір батьків, а другий – досягти більшого різноманіття, що важливо в задачі з генерації тестових даних. Тому в роботі пропонується гібридний метод
відбору на основі цих методів. Перед початком відбору необхідно визначити, яка частина нового покоління буде отримана перенесенням кращих хромосом, а яка – в результаті схрещування. Емпірично для задачі генерації тестових даних були визначені наступні параметри. Як кращі хромосоми для перенесення в нове покоління без змін вибираються 20% хромосом з найбільшою функцією пристосованості, що складає пул кращих Pbest. Решта 80% хромосом нового покоління будуть відібрані з використанням гібридного методу:– 50% хромосом для схрещування обираються лише з пула Pbest;
- 50% хромосом будуть відібрані з популяції взагалі, тобто значення функції пристосованості не враховується. Схрещування серед усіх хромосом необхідно для досягнення більшого різноманіття популяції. Таким чином, ми можемо зберегти хромосоми, які потенційно (на наступних ітераціях) можуть призвести до появи складних шляхів коду, виходу на які ускладнений системою обмежень, що містяться в умовних операторах тестового коду. Отже, гібридний метод дозволяє краще досліджувати тестовий код та відбирати хромосоми з метою досягнення більшого різноманіття. Після відбору пари батьківських хромосом, вони формують одного нащадка з використанням еволюційної операції схрещування.
Схрещування дозволяє отримувати нові набори тестових даних шляхом перемішування значень вже існуючих. У термінах генетичного алгоритму, дві батьківські хромосоми обмінюються генами для отримання нащадка. Основна мета використання схрещування полягає в ітеративному поліпшенні покоління шляхом послідовного схрещування найкращих хромосом для отримання кращих рішень. У цій роботі схрещування також використовується для збільшення різноманітності популяції за допомогою гібридного методу відбору.
Змішування необхідне для отримання нових значень генів у популяції, що є ключовим для створення нових значень у неперервному варіанті ГА.
Мутація є еволюційною операцією, яка дозволяє вводити нові значення в популяцію шляхом випадкової зміни генів. Мутація застосовується лише до нащадків, тому найкращі набори тестів, що безпосередньо передаються в нове покоління (без операції схрещування), не зазнають змін. Дуже важливо встановити вірну ймовірність мутації, оскільки надто мала ймовірність може усунути переваги мутації в цілому, і алгоритм може не знаходити набори тестів для переходу на більш складні шляхи. Занадто велика ймовірність, навпаки, буде непередбачувано змінювати нащадків, що може усунути переваги використання ГА порівняно з випадковим пошуком.
Генетичні алгоритми є потужним інструментом для генерації тестових даних у контексті тестування програмного забезпечення. Розуміння їх основних концепцій та застосування генетичних алгоритмів для генерації тестових даних сприяє вдосконаленню процесів тестування та досліджень у багатьох галузях розробки програмного забезпечення. Також проведено аналіз основних концепцій еволюційних операцій, такі як селекція, схрещування, змішування, мутація, у контексті їх застосування для створення оптимальних тестових наборів даних.